Task Details
The task consists of identifying which product specifications (in short, specs) from multiple e-commerce websites represent the same real-world product.
You are provided with a dataset including ~30k specs in JSON format, each spec containing a list of (attribute_name, attribute_value) pairs extracted from a different web page, collected across 24 different web sources. We will refer to this dataset as dataset X.
- Each spec is stored as a file, and files are organized into directories, each directory corresponding to a different web source (e.g., www.alibaba.com).
- All specs refer to cameras and include information about the camera model (e.g. Canon EOS 5D Mark II) and, possibly, accessories (e.g. lens kit, bag, tripod). Accessories do not contribute to product identification: for instance, a Canon EOS 5D Mark II that is sold as a bundle with a bag represents the same core product as a Canon EOS 5D Mark II that is sold alone.
{
"<page title>": "Samsung Smart WB50F Digital Camera White Price in India with Offers & Full Specifications | PriceDekho.com",
"brand": "Samsung",
"dimension": "101 x 68 x 27.1 mm",
"display": "LCD 3 Inches",
"pixels": "Optical Sensor Resolution (in MegaPixel)\n16.2 MP"
"battery": "Li-Ion"
}
Note that, while the page title attribute is always present, all other attribute names can vary (even within the same web source). Note also that two attributes with the same name (homonyms) might have different semantics (e.g. "battery" that can refer to "battery type", like "AAA", or "battery chemistry", like "Li-Ion"), and that two attributes with the same semantics (synonyms) might have different names (e.g., "resolution" and "pixels").
You are also provided with a labelled dataset in CSV format, containing three columns: "left_spec_id", "right_spec_id" and "label". We will refer to this dataset as dataset W (which includes the previously released labelled dataset, referred to as dataset Y).
- The "spec_id" is a global identifier for a spec and consists of a relative path of the spec file. Note that instead of "/" the spec_id uses a special character "//" and that there is no extension. For instance, the spec_id "www.ebay.com//1000" refers to the 1000.json file inside the www.ebay.com directory. All "spec_id" in the labelled dataset W refer to product specs in dataset X. Thus, the dataset W provides labels for a subset of the product pairs in the Cartersian product of the specs dataset X with itself.
- Each row of the labelled dataset represents a pair of specifications. Label=1 means that the left spec and the right spec refer to the same real-world product (in short, that they are matching). Label=0 means that the left spec and the right spec refer to different real-world products (in short, that they are non-matching).
left_spec_id, right_spec_id, label
www.ebay.com//1, www.ebay.com//2, 1
www.ebay.com//3, buy.net//10, 0
Note that there might be matching pairs even within the same web source, and that the labelled dataset W is transitively closed (i.e., if A matches with B and B matches with C, then A matches with C).
More details about the datasets can be found in the dedicated "Datasets" section.
Your goal is to find all pairs of product specs in dataset X that match, that is, refer to the same real-world product. Your output must be stored in a CSV file containing only the matching spec pairs found by your system. The CSV file must have two columns: "left_spec_id" and "right_spec_id": each row in this CSV file consists of just two ids, separated by comma.
Example of output CSV file
left_spec_id, right_spec_id
www.ebay.com//10, www.ebay.com//20
www.ebay.com//10, buy.net//100
An example CSV file is also included in the Quick Start Package (see "Submitting" section).
Datasets
| Dataset X | Specs Dataset | 8.5 Mb (compressed) |
| Dataset Y | Labelled Dataset (Medium) | 2.1 Mb |
| Dataset W | Labelled Dataset (Large) | 13.0 Mb |
Note that the labelled dataset W (which includes the previously released labelled dataset, referred to as dataset Y) provided to participants is disjoint from the held-out dataset used in the evaluation process. More details about the evaluation process can be found in the dedicated "Evaluation Process" section.
Submitting
Before submitting, participants need to register here. After registration each team will receive by e-mail (within 1 working day) an alphanumeric Team ID that will be used for the submissions.
Submissions must include only the output CSV file described in the "Task Details" section. A team can make multiple submissions, that is, submit multiple CSV files. The last submitted CSV file will override the previous submitted files.
In order to make a new submission, participants need to use this submission form. In every submission, participants need to fill the submission form always with their Team ID.
You can use the quick start package as a starting point: it contains mock data (in the same format of the datasets X and W) and an elementary solution (in Python).
Evaluation Process
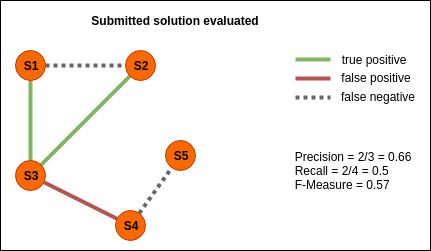
Submitted solutions are ranked on the basis of F-measure (the harmonic mean of precision and recall), rounded up to two decimal places. Precision and recall are computed w.r.t. a secret evaluation dataset. We will refer to this dataset as dataset Z.
For clarity purposes, the two graphs below represent a sample submitted solution and the evaluation dataset Z respectively. In the graphs, nodes represent specs and edges represent matching relationships.
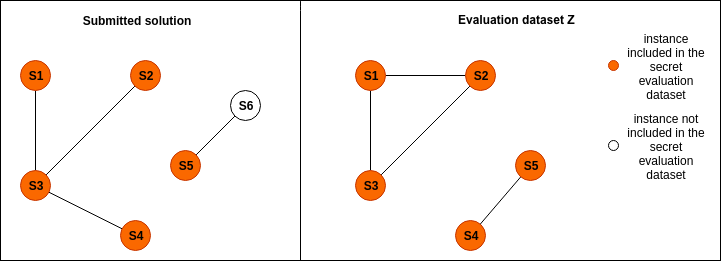
Precision and recall of the submitted solution will be evaluated only on the edges in which both nodes are included in the evaluation dataset Z, as illustrated in the figure below.
Note that edges in the evaluation dataset Z are disjoint from the edges in the labelled datasets W (which includes Y). Specifically, the labelled dataset W includes a random selection of camera models from the evaluation dataset Z and, for each camera model, a random selection of specs referring to it.
The leaderboard is updated periodically and shows the score of the most recent submission for each team at that time. As discussed above, labelled dataset W provided to participants is not included in a submission's score (valid from the next leaderboard update).
Note that the leaderboard update published at 23.47 of 03/01/2020 is the last involving dataset Y.
FinalistsAfter the final challenge deadline, we will reproduce the results of teams in the leaderboard in rank order and select as finalists the first 5 teams whose submission is reproduced. During this process, teams will be invited to submit:
- a link to their code;
- a guide on how to run (and train, if needed) their code.
New Submissions will be unpacked, manually inspected, compiled and tested in a network-isolated container with characteristics shown in the table below. We assume that a submission may have a training step and a resolution step. In order to break down training time and resolution time fairly, the reproduction process for both steps will follow the schema below. If you feel that your solution would not trivially fit in such a schema and you aim at being selected as a finalist, please send us an email before March 30th and we will provide instructions.
- Training step (optional)
Admitted Input: the W dataset, the specs in the X dataset whose spec_id appears in the W dataset, publicly available auxiliary data (e.g. a list of camera manufacturer), hyperparameters.
Time Limit: 12h
Required Output: a text or a binary file F with the result of the training process. - Resolution step (mandatory)
Admitted Input: the X dataset, the file F (if needed).
Time Limit: 12h
Required Output: the output CSV file C.
| Processor | 4 x 3.0 GHz |
| Main Memory | 16 Gb |
| Storage | 128 Gb |
| Operating System | Linux |
The winner and the runner-up will be selected among the 5 finalists based on their original submitted solution F-measure. Ties will be broken based on running time for creating the solution file (training excluded) in our environment during the reproduction process.
Rules
- The 2020 SIGMOD Programming Contest is open to undergraduate and graduate students from degree-granting institutions all over the world. However, students associated with the organizers' institution (Roma Tre University, Italy) are not eligible to participate.
- Teams must consist of individuals currently registered as graduate or undergraduate students at an accredited academic institution. A team may be formed by one or more students, who do not need to be enrolled in the same institution. Several teams from the same institution can compete independently, but one person can be a member of only one team. There is no limit on team size.
- All submissions must consist only of code written by the team or open source licensed software (i.e., using an OSI-approved license). For source code from books or public articles, clear reference and attribution must be made. Final submissions must be made by 03 April 2020 (anywhere on Earth).
- All teams must agree to license their code under an OSI-approved open source license. By participating in this contest, each team agrees to publish its source code. The finalists' implementations will be made public on the contest website.
- A team is eligible for the prize if at least one of its members will come to present the work at the SIGMOD 2020 conference. The travel grants will only be granted to eligible teams.